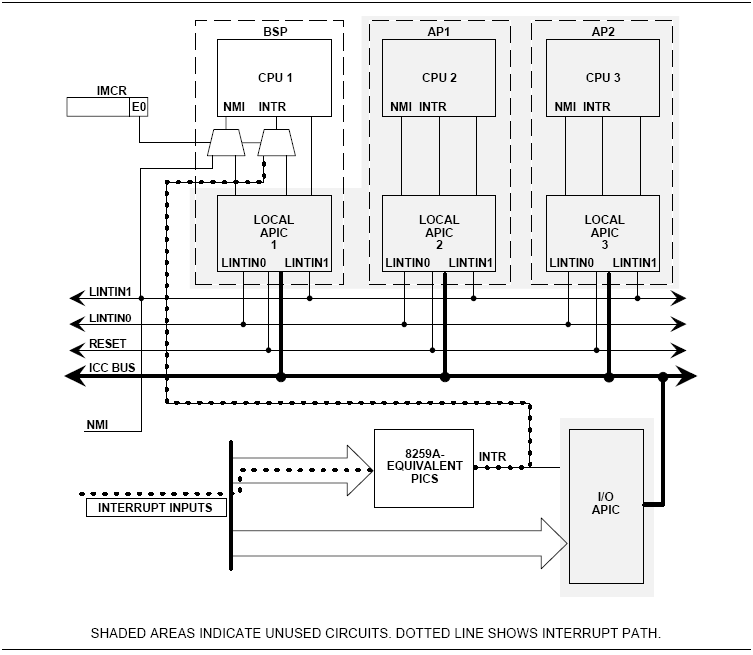
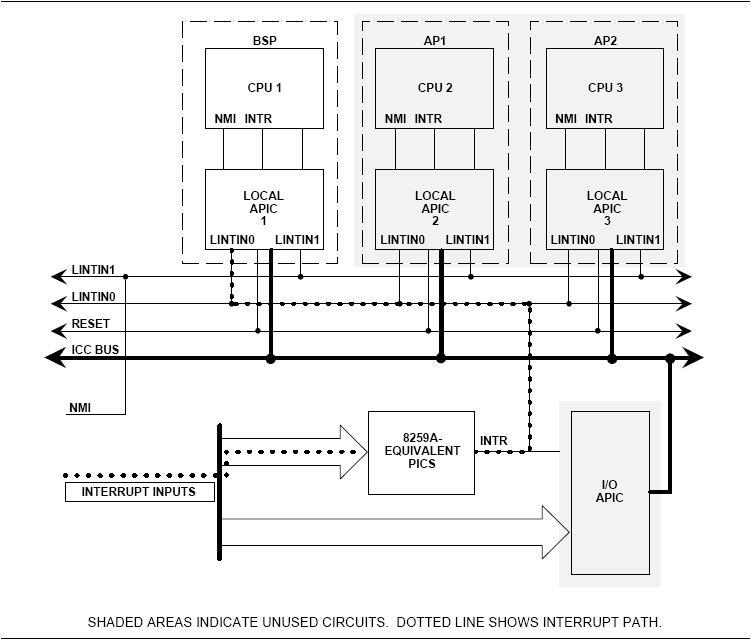
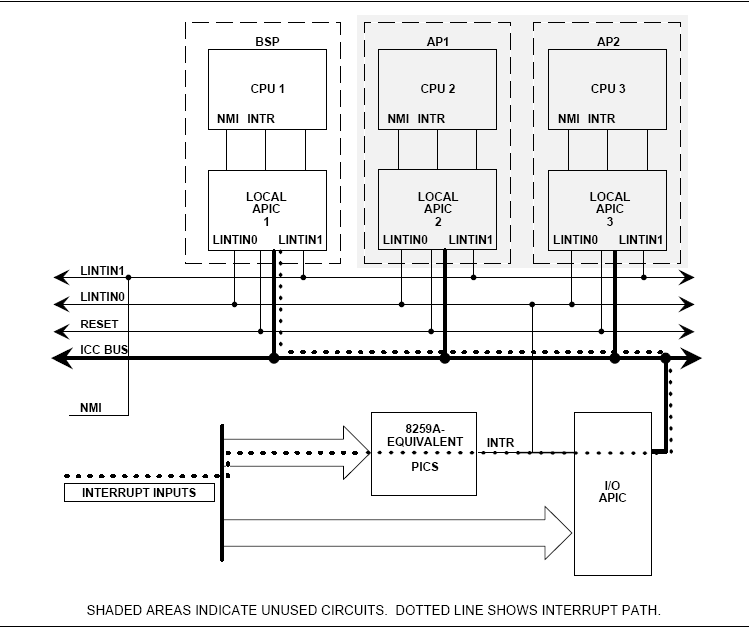
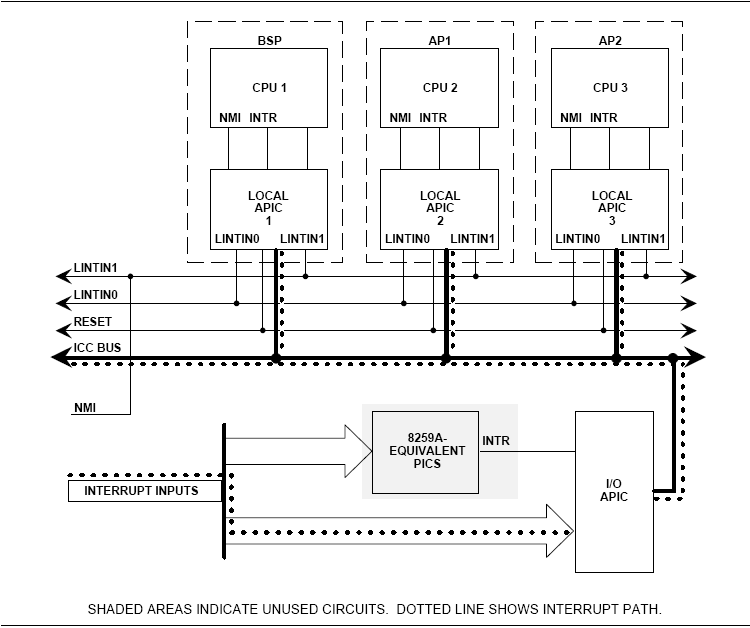
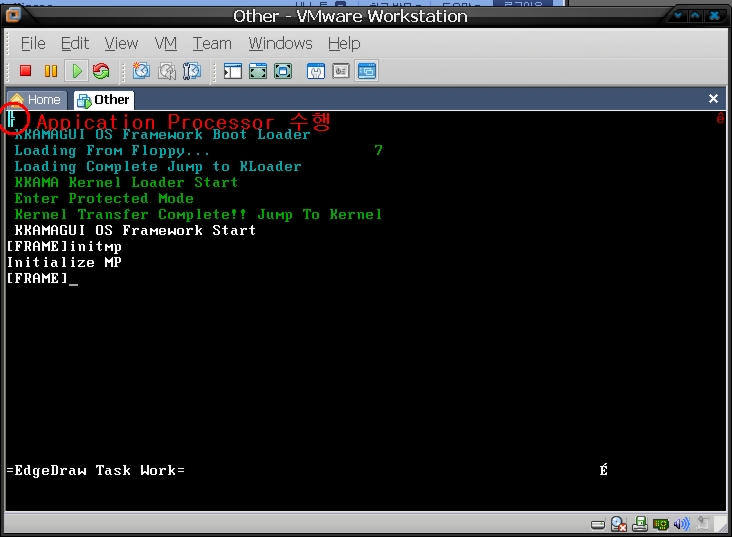
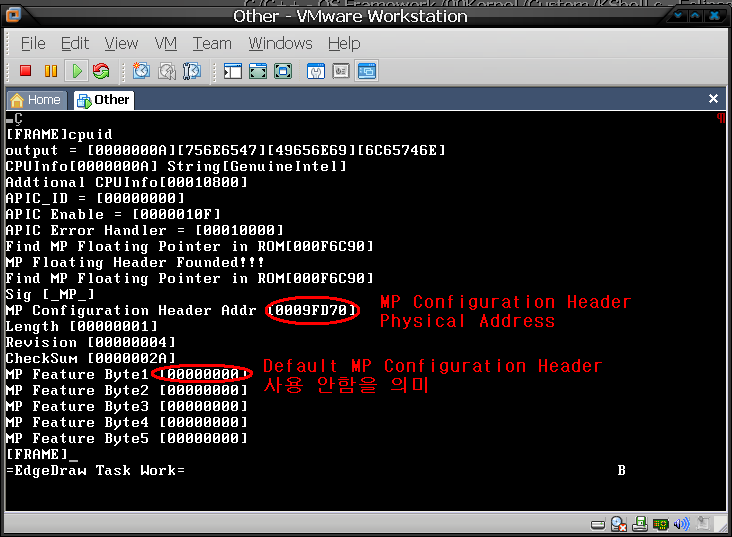
예전에 개발하면서 적어놓았던 것인데, 블로그가 이전되서 다시 옮겨왔습니다. ^^
< 2004 05 11 GUI ( Graphic User Interface) >
으옷... @0@/~ 드뎌 네모난 커서에서 벗어났습니다 ㅋㅋㅋ 이틀동안 삽질한 끝에
Icon 파일을 읽어 낼 수가 있게 되었네요.. 화면 중앙에 보시면 콘솔위에 삼각형의
하늘색 커서가 있음을 알 수 있습니다. 요 아래쪽의 스샷을 보시면 파란색 네모가
동동~ 떠있는데, 고게 Icon 파일의 힘으로 삼각형으로.. ㅡ0ㅠ.. 감동..
< 2004 05 08 GUI ( Graphic User Interface) >
윈도우의 폰트가 기존의 래스터에서 돋움체로 바뀌어서 한컷 찍어 올립니다. 양쪽에
는 뽀대를 살리기위한 비트맵 로더가 떠있구요, 가운데 보시면 돋움으로 무장한
GUI Shell이 오랜지색 커서와 함께 두둥 떠 있는 걸 보실 수 있습니다.
으흣.. 폰트가 바뀌니 훨씬 나아 보이는군요.. ㅋㅋㅋ
앗쌀~ 홧팅 @0@/~
< 2004 05 06 GUI ( Graphic User Interface) >
아아.. 오래간만에 한컷 올립니다. 에궁에궁 출장이다 머다 해서 한동안 손을 조금
놓고있었기때문에, 헐헐헐..
이번에 스샷의 관전 포인트(??)는 제 마스코트랑 열혈강호가 올라가있는 BMP Viewer
가 아니라, 요것들이 모두 Application, 즉 User Level의 프로그램들이라는 것에 초점
을 맞추어야 한다고.. 쿠.. 쿨럭..;;;;
그리고 GUI Console에 오랜지색 네모 커서도 넣었고, 윈도우 테두리도 녹색에서
오랜지 빛으로 바꾸었습니다. 이게 더 보기가 좋군요.. ㅋㅋㅋ
일단 곧 커널이랑 하드 이미지도 릴리즈를.. 글고.. 곧 소스도..
쿠.. 쿨럭..;;; 정리는 안하고 지저분하게 삽질만 계속 하고 있는..
까.. 마.. 구.. @0@/~
< 2004 04 11 GUI ( Graphic User Interface) >
위에서 보시는 스샷은 아래의 4월 3일자의 스샷과 별 차이가 없는데요, 사실 비슷하긴
한데, 내부적으로는 상당한 변화가 있었기때문에 기념으로 한컷 올립니다.
으읏 진짜 이번엔 문제가 너무 심각해서 며칠째 고심해서 고쳤는지 ㅡ0ㅠ...
이번에 수정하면서 그런생각이 들더군요.. 과연 이 삽질의 끝에는 머가 있을까..
굉장히 궁금합니다 그려.. ㅋㅋㅋㅋ
4월 3일자에서 있었던 키의 문제는 해결한 스샷입니다. 사실 외관은 똑같군요..
( 아아.. 암것도 안한거 같오.. ㅡ0ㅠ... 억울..크윽.. )
< 2004 04 03 GUI ( Graphic User Interface) >
이번에 구현된 GUI system call을 테스트 하기 위해 만든 Application입니다.
기본적으로 하는일은, CUI에서 보여지는 80 * 25의 Text 화면을 그대로 옮겨서 보여
주는 것이지요.
아직 Key 문제가 확실히 해결되지 않아서 약간 문제가 있지만 그런대로
볼만은 하군요.. ㅋㅋㅋㅋ
< 2004 03 23 ETC ( ^ㅠ^ ) >
제가 목표로 하고 있는 GUI의 모습입니다.
Evil WM 이라고 굉장히 가볍다고 하는군요. 저는 윈도우를 쓰기때문에 잘 모름..
그러나 딱 봤을때 이미 필이 왔죠.. 보면 볼수록 멋집니다.
@0@/~~
< 2004 03 27 CUI ( Console User Interface) >
첫번째 화면은 이번에 릴리즈된 커널을 Bochs에서 돌린 화면입니다.
showdevice 했을때, com1, HDD, RamDisk 순으로 보이는 군요.
기본적으로 다 Mount된 상태로 실행되게 했습니다.
이게 테스트 하긴 더 편하더라구요..
두번째 화면은 KKAMAGUI Editor를 돌린 화면입니다. 간단한 텍스트를 입력하고,
/a.txt로 저장했어요.
세번째 화면은 KKAMAGUI Editor를 돌려 시리얼로 전송받은 소스코드를 읽은
화면이에요. 제가 짠건 아니지만 걍 있길래 전송해서 열어봤죠.. >_<
< 2004 03 24 CUI ( Console User Interface) >
이번에 릴리즈된 커널을 Bochs에서 돌린 화면입니다. showdevice 했을때,
램 디스크 하나랑 시리얼 포트, 그리고 추가된 하드가 보이는군요.
아참 램 디스크( rd0 )는 이번 커널에는 아니고.. 곧 릴리즈될 커널에 있는 건데..
Screen shot이 잘못됬네요.. 여튼 '/'에 Mount 한다음 내용물을 보여준겁니다.
므흣.. 좋네요~ ^0^/~
< 2004 03 23 ETC ( ^ㅠ^ ) >
제가 주로 쓰는 kkamagui를 그려봤습니다. 아마 지난 설인걸로 기억하는데요..
ㅋㅋㅋ 그때 별로 할일이 없어서 그림판으로 그렸던듯 하군요
그냥 한번 웃어보시라구요 ^0^/~
< 2004 03 15 CUI ( Console User Interface) >
CUI Screen shot 입니다. 맨 위에 화면은 처음 부팅했을때 보이는 화면입니다.
오늘 페이지를 추가하면서 생긴 화면이네요.. ^^
두번째 화면은 Worms라고 제가 공유메모리를 구현하고 그걸 테스트하기위해 만든
프로그램입니다. 처음에 녹색 한마리가 이리저리 돌아다니는데요, 이게 일정시간
지나면 상태도 변하고 그에 따라 먹이도 먹고 분열도 하고 싸움도 하는 그런 프로그램
입니다. 머 알고리즘이 그리 복잡하지 않기 때문에 크게 변화는 없구요.
주기적으로 늘었다 줄었다 하는군요. 심심하신 분은 한번 실행해 보심이.. ㅋㅋ
< 2004 03 14 CUI ( Console User Interface) >
CUI Screen shot 입니다. 맨 위에 화면을 보시면 Device 목록에 hda0 및 hdc0 두개의
하드디스크와 시리얼 포트 2개가 있음을 알 수 있습니다.
mount 명령으로 /에 hdc0를 mount하고 ls를 통해 파일을 조회한 화면입니다.
두번째 화면은 B2OS를 만드신 분이 CUI버전으로 테트리스를 제작하셨는데요, 그걸
그대로 포팅해서 제 OS에 돌린 화면입니다. ^^
B2OS 주인장님께 거듭 감사를 드립니다. (_ _)
< 2004 03 14 BoxBox Prototype>
GUI Prototype Screen shot 입니다. 이름은 BoxBox이구요. 사각형으로 이루어진
간단한 GUI를 목표로 하고 있기 때문에 이름을 이렇게 지었습니다.
커서( 가운데의 하얀 사각형 )의 모양까지 현재는 사각형을 띄고 있는데요,
조만간 커서는 삼각형으로 만들어볼까 생각중입니다. ㅋㅋ
윈도우는 evilwm에 영향을 받아서 녹색의 1 pixel로 이루어져 있구요, 내부는
녹색을 약간띄는 어두운 색으로 맞추어놨습니다.
테스트를 위해 여러 윈도우를 겹쳐놨는데, 생각난김에 한컷 잡아서 올립니다.
볼수록 모노크롬 모니터 시절을 생각나게 하는군요. ^^
개인적으로는 아주 맘에 드는데 말이죠. ㅋㅋ
이런 멋진 GUI를 만들게 해주신 Linefeed 님과 Ed 님께 감사를.. ㅎㅎ