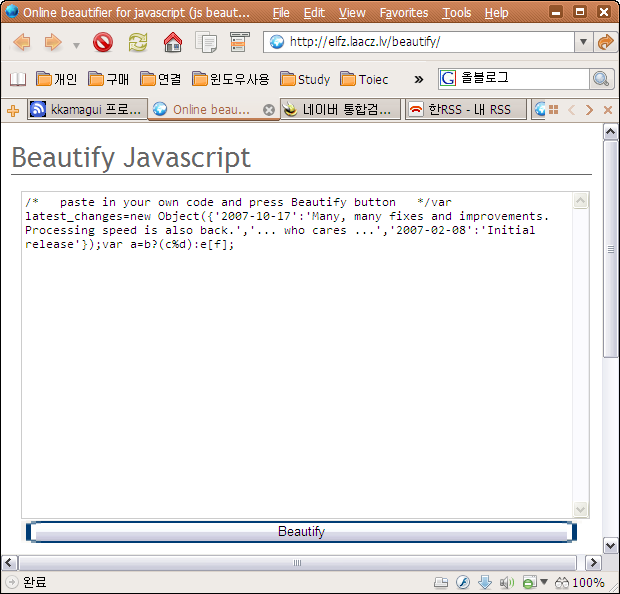
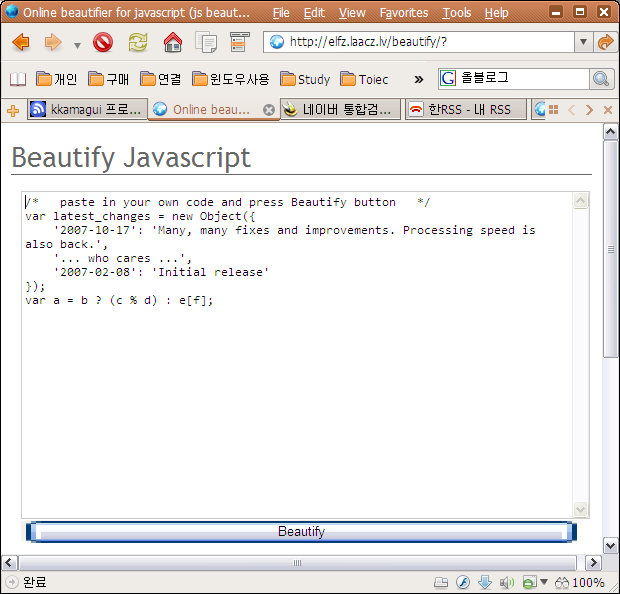
12 문자셋(Character Set) 자동 탐지
원문 : http://www.mozilla.org/projects/intl/UniversalCharsetDetection.html
A composite approach to language/encoding detection
Shanjian Li (shanjian@netscape.com)
Katsuhiko Momoi (momoi@netscape.com)
Netscape Communications Corp.
[Note: This paper was originally presented at the 19th International Unicode Conference (San Jose). Since then the implementation has gone through a period of real world usage and we made many improvements along the way. A major change is that we now use positive sequences to detect single byte charsets, c.f. Sections 4.7 and 4.7.1. This paper was written when the universal charset detection code was not part of the Mozilla main source. (See Section 8). Since then, the code was checked into the tree. For more updated implementation, see our open source code at Mozilla Source Tree. - The authors. 2002-11-25.]
1. Summary:
This paper presents three types of auto-detection methods to determine encodings of documents without explicit charset declaration. We discuss merits and demerits of each method and propose a composite approach in which all 3 types of detection methods are used in such a way as to maximize their strengths and complement other detection methods. We argue that auto-detection can play an important role in helping transition browser users from frequent uses of a character encoding menu into a more desirable state where an encoding menu is rarely, if ever, used. We envision that the transition to the Unicode would have to be transparent to the users. Users need not know how characters are displayed as long as they are displayed correctly -- whether it’s a native encoding or one of Unicode encodings. Good auto-detection service could help significantly in this effort as it takes most encoding issues out of the user’s concerns.
2. Background:
Since the beginning of the computer age, many encoding schemes have been created to represent various writing scripts/characters for computerized data. With the advent of globalization and the development of the Internet, information exchanges crossing both language and regional boundaries are becoming ever more important. But the existence of multiple coding schemes presents a significant barrier. The Unicode has provided a universal coding scheme, but it has not so far replaced existing regional coding schemes for a variety of reasons. This, in spite of the fact that many W3C and IETF recommendations list UTF-8 as the default encoding, e.g. XML, XHTML, RDF, etc. Thus, today's global software applications are required to handle multiple encodings in addition to supporting Unicode.
The current work has been conducted in the context of developing an Internet browser. To deal with a variety of languages using different encodings on the web today, a lot of efforts have been expended. In order to get the correct display result, browsers should be able to utilize the encoding information provided by http servers, web pages or end users via a character encoding menu. Unfortunately, this type of information is missing from many http servers and web pages. Moreover, most average users are unable to provide this information via manual operation of a character encoding menu. Without this charset information, web pages are sometimes displayed as ‘garbage’ characters, and users are unable to access the desired information. This also leads users to conclude that their browser is mal-functioning or buggy.
As more Internet standard protocols designate Unicode as the default encoding, there will undoubtedly be a significant shift toward the use of Unicode on web pages. Good universal auto-detection can make an important contribution toward such a shift if it works seamlessly without the user ever having to use an encoding menu. Under such a condition, gradual shift to Unicode could be painless and without noticeable effects on web users since for users, pages simply display correctly without them doing anything or paying attention to an encoding menu. Such a smooth transition could be aided by making encodings issues less and less noticeable to the users. Auto-detection would play an important role for such a scenario.
3. Problem Scope:
3.1. General Schema
Let us begin with a general schema. For most applications, the following represents a general framework of auto-detection use:
Input Data -> Auto-detector -> Returns results
An application/program takes the returned result(s) from an auto-detector and then uses this information for a variety of purposes such as setting the encoding for the data, displaying the data as intended by the original creator, pass it on to other programs, and so on.
The auto-detection methods discussed in this paper use an Internet Browser application as an example. These auto-detection methods, however, can be easily adapted for other types of applications.
3.2. Browser and auto-detection
Browsers may use certain detection algorithms to auto-detect the encoding of web pages. A program can potentially interpret a piece of text in any number of ways assuming different encodings, but except in some extremely rare situations, only one interpretation is desired by the page’s author. This is normally the only reasonable way for the user to see that page correctly in the intended language.
To list major factors in designing an auto-detection algorithm, we begin with certain assumptions about input text and approaches to them. Taking web page data as an example,
1. Input text is composed of words/sentences readable to readers of a particular language. (= The data is not gibberish.)
2. Input text is from typical web pages on the Internet. (= The data is usually not from some dead or ancient language.)
3. The input text may contain extraneous noises which have no relation to its encoding, e.g. HTML tags, non-native words (e.g. English words in Chinese documents), space and other format/control characters.
To cover all the known languages and encodings for auto-detection is nearly an impossible task. In the current approaches, we tried to cover all popular encodings used in East Asian languages, and provided a generic model to handle single-byte encodings at the same time. The Russian language encodings was chosen as an implementation example of the latter type and also our test bed for single-byte encodings.
4. Target multi-byte encodings include UTF8, Shift-JIS, EUC-JP, GB2312, Big5, EUC-TW, EUC-KR, ISO2022-XX, and HZ.
5. Providing a generic model to handle single-byte encodings – Russian language encodings (KOI8-R, ISO8859-5, window1251, Mac-cyrillic, ibm866, ibm855) are covered in a test bed and as an implementation example.
4. Three Methods of Auto-detection:
4.1. Introduction:
In this section, we discuss 3 different methods for detecting the encoding of text data. They are 1) Coding scheme method, 2) Character Distribution, and 3) 2-Char Sequence Distribution. Each one has its strengths and weaknesses used on its own, but if we use all 3 in a complementary manner, the results can be quite satisfying.
4.2. Coding Scheme Method:
This method is probably the most obvious and the one most often tried first for multi-byte encodings. In any of the multi-byte encoding coding schemes, not all possible code points are used. If an illegal byte or byte sequence (i.e. unused code point) is encountered when verifying a certain encoding, we can immediately conclude that this is not the right guess. A small number of code points are also specific to a certain encoding, and that fact can lead to an immediate positive conclusion. Frank Tang (Netscape Communications) developed a very efficient algorithm to detecting character set using coding scheme through a parallel state machine. His basic idea is:
For each coding scheme, a state machine is implemented to verify a byte sequence for this particular encoding. For each byte the detector receives, it will feed that byte to every active state machine available, one byte at a time. The state machine changes its state based on its previous state and the byte it receives. There are 3 states in a state machine that are of interest to an auto-detector:
- START state: This is the state to start with, or a legal byte sequence (i.e. a valid code point) for character has been identified.
- ME state: This indicates that the state machine identified a byte sequence that is specific to the charset it is designed for and that there is no other possible encoding which can contain this byte sequence. This will to lead to an immediate positive answer for the detector.
- ERROR state: This indicates the state machine identified an illegal byte sequence for that encoding. This will lead to an immediate negative answer for this encoding. Detector will exclude this encoding from consideration from here on.
In a typical example, one state machine will eventually provide a positive answer and all others will provide a negative answer.
The version of PSM (Parallel State Machine) used in the current work is a modification of Frank Tang's original work. Whenever a state machine reaches the START state, meaning it has successfully identified a legal character, we query the state machine to see how many bytes this character has. This information is used in 2 ways.
- First, for UTF-8 encoding, if several multi-byte characters are identified, the input data is very unlikely to be anything other than UTF-8. So we count the number of multi-byte characters identified by the UTF-8 state machine. When it reaches a certain number (= the threshold), conclusion is made.
- Second, for other multi-byte encodings, this information is fed to Character Distribution analyzer (see below) so that the analyzer can deal with character data rather than raw data.
4.3. Character Distribution Method:
In any given language, some characters are used more often than other characters. This fact can be used to devise a data model for each language script. This is particularly useful for languages with a large number of characters such as Chinese, Japanese and Korean. We often hear anecdotally about such distributional statistics, but we have not found many published results. Thus for the following discussions, we relied mostly on our own collected data.
4.3.1. Simplified Chinese:
Our research on 6763 Chinese characters data encoded in GB2312 shows the following distributional results:
| Number of Most Frequent Characters |
Accumulated Percentage |
| 10 |
0.11723 |
| 64 |
0.31983 |
| 128 |
0.45298 |
| 256 |
0.61872 |
| 512 |
0.79135 |
| 1024 |
0.92260 |
| 2048 |
0.98505 |
| 4096 |
0.99929 |
| 6763 |
1.00000 |
Table 1. Simplified Chinese Character Distribution Table
4.3.2. Traditional Chinese:
Research by Taiwan’s Mandarin Promotion Council conducted annually shows a similar result for traditional Chinese encoded in Big5.
|
Number of Most Frequent Characters
|
Accumulated Percentage
|
| 10 |
0.11713
|
| 64 |
0.29612
|
| 128 |
0.42261
|
| 256 |
0.57851
|
| 512 |
0.74851
|
| 1024 |
0.89384
|
| 2048 |
0.97583
|
| 4096 |
0.99910
|
| |
|
Table 2. Traditional Chinese Character Distribution Table
4.3.3. Japanese:
We collected our own data for Japanese, then wrote a utility to analyze them. The following table shows the results:
| Number of Most Frequent Characters |
Accumulated Percentage |
| 10 |
0.27098 |
| 64 |
0.66722 |
| 128 |
0.77094 |
| 256 |
0.85710 |
| 512 |
0.92635 |
| 1024 |
0.97130 |
| 2048 |
0.99431 |
| 4096 |
0.99981 |
| |
1.00000 |
Table 3. Japanese Character Distribution Table
4.3.4. Korean:
Similarly for Korean, we collected our own data from the Internet and run our utility on it. The results are as follows:
| Number of Most Frequent Characters |
Accumulated Percentage |
| 10 |
0.25620 |
| 64 |
0.64293 |
| 128 |
0.79290 |
| 256 |
0.92329 |
| 512 |
0.98653 |
| 1024 |
0.99944 |
| 2048 |
0.99999 |
| 4096 |
0.99999 |
| |
|
Table 4. Korean Character Distribution Table
4.4. General characteristics of the distributional results:
In all these four languages, we find that a rather small set of coding points covers a significant percentage of characters used in our defined application scope. Moreover, closer examination of those frequently used code points shows that they are scattered over a rather wide coding range. This gives us a way to overcome the common problem encountered in the Coding Scheme analyzer, i.e. different national encodings may share overlapping code points. Because the most frequently occurring sets for these languages have the characteristics described above, the overlap problem between different encodings in the Code Scheme Method will be insignificant in the Distribution Method.
4.5. Algorithm for analysis:
In order to identify characteristics of a language based on the character frequency/distribution statistics, we need an algorithm to calculate a value from a stream of text input. This value should show the likelihood of this stream of text being in a certain character encoding. A natural choice might be to calculate this value based on each character’s frequency weight. But from our experiment with various character encodings, we find that this approach is not necessary and it uses too much memory and CPU power. A simplified version provides a very satisfactory result, and uses much less resources and runs faster.
In the current approach, all characters in a given encoding are classified into 2 categories, “frequently used” and “not frequently used”. If a character is among the top 512 characters in the frequency distribution table, it is categorized as a “frequently used” character. The number 512 is chosen because it covers a significant amount of accumulated percentages in any of the 4 language input text while only occupying a small percentage of coding points. We count the number of characters in either category in a batch of input text, and then calculate a float value we call Distribution Ratio.
The Distribution Ratio is defined as follows:
Distribution Ratio = the Number of occurrences of the 512 most frequently used characters divided by the Number of occurrences of the rest of the characters.
Each of the multi-byte encodings tested actually shows a distinct Distribution Ratio. From this ratio then, we can calculate the confidence level of the raw input text for a given encoding. Following discussions for each encoding should make this clearer.
4.6. Distribution Ratio and Confidence Level:
Let us look at the 4 language data to see the differences in Distribution Ratios. Note first that we use the term Distribution Ratio in two ways. An “ideal” Distribution Ratio is defined for language scripts/character sets rather than for encodings. If a language script/character set is represented by more than one encodings, then, for each encoding, we calculate the “actual” Distribution Ratio in the input data by sorting characters into “frequently used” or “not frequently used” categories. This value is then compared against the ideal Distribution Ratio of the language script/character set. Based on the actual Distribution Ratios obtained, we can calculate the Confidence level for each set of input data as described below.
4.6.1. Simplified Chinese (GB2312):
GB2312 encoding contains two levels of Chinese characters. Level 1 contains 3755 characters, and Level 2, 3008 characters. Level 1 characters are more frequently used than Level 2 ones, and it is no surprise to see that all 512 characters on the most frequently used character list for GB 2312 are within Level 1. Because Level 1 characters are sorted based on pronunciation, those 512 characters are evenly scattered in 3755 code points. These characters occupies 13.64% of all coding points in Level 1, but it covers 79.135% of the character occurrences in a typical Chinese text. In an ideal situation, a piece of Chinese text that contains enough characters should return us something like:
Distribution Ratio = 0.79135/(1-0.79135) =3.79
And for a randomly generated text using the same encoding scheme, the ratio should be around 512 / (3755-512)=0.157 if no level 2 character is used.
If we include Level 2 characters into consideration, we can assume that the average probability of each Level 1 character is p1, and that of Level 2 is p2. The calculation then would be:
512*p1 / (3755*p1 + 3008*p2 – 512*p1) = 512/(3755 + 3008*p2/p1-512)
Obviously, this value is even smaller. In a later analysis, we just use the worst case for comparison.
4.6.2. Big 5:
Big5 and EUC-TW (i.e. CNS Character Set) encodings have a very similar story. Big5 also encodes Chinese characters in 2 levels. The most frequently used 512 characters are evenly scattered in 5401 Level 1 characters. The ideal ratio we can get from a big5-encoded text is:
Distribution Ratio = 0.74851/(1-0.74851) =2.98
And for a randomly generated text should have a ration near
512/(5401-512)=0.105
Since Big5 Level 1 characters are nearly identical to CNS plane 1 characters, the same analysis applies to EUC-TW.
4.6.3. Japanese Shift_JIS & EUC-JP:
For the Japanese Language, Hiragana and Katakana are usually more frequently used than Kanji. Because Shift-JIS and EUC-JP encode Hiragana and Katakana in different coding ranges, we are still able to use this method to distinguish among the two encodings.
Those Kanji characters that are among the most 512 frequently used characters are also scattered evenly among 2965 JIS Level 1 Kanji set. The same Analysis leads to the following distribution ratio:
Distribution Ratio = 0.92635 / (1-0.92635) = 12.58
For randomly generated Japanese text data, the ratio should be at least
512 / (2965+63+83+86-512) = 0.191.
The calculation includes Hankaku Katakana (63), Hiragana (83), and Katakana (86).
4.6.4. Korean EUC-KR:
In EUC-KR encoding, the number of Hanja (Chinese) characters actually used in a typical Korean text is insignificant. The 2350 Hangul characters coded in this encoding are arranged by their pronunciation. In the frequency table we got through analyzing a large amount of Korean text data, most frequently used characters are evenly distributed in these 2350 code points. Using the same analysis, in an ideal situation, we get:
Distribution Ratio = 0.98653 / (1-0.98653) = 73.24
For randomly generated Korean text, it should be:
512 / (2350-512) = 0.279.
4.6.5. Calculating Confidence Level:
From the foregoing discussions for each language script, we can define the Confidence level for each data set as follows:
Confidence Detecting(InputText)
{
for each multi-byte character in InputText
{
TotalCharacterCount++;
if the character is among 512 most frequent ones
FrequentCharacterCount++;
}
Ratio = FrequentCharacterCount
/ (TotalCharacterCount-FreqentCharacterCount);
Confidence = Ratio / CHARSET_RATIO;
Return Confidence;
}
The Confidence level for a given set data is defined as the Distribution Ratio of the input data divided by the ideal Distribution Ratio obtained by the analyses in the preceding sections.
4.7. Two-Char Sequence Distribution Method:
In languages that only use a small number of characters, we need to go further than counting the occurrences of each single character. Combination of characters reveals more language-characteristic information. We define a 2-Char Sequence as 2 characters appearing immediately one after another in input text, and the order is significant in this case. Just as not all characters are used equally frequently in a language, 2-Char Sequence distribution also turns out to be extremely language/encoding dependent. This characteristic can be used in language detection. This leads to better confidence in detecting a character encoding, and is very useful in detecting single byte languages.
Let’s use Russian language as an example. We downloaded around 20MB of Russian plain text, and wrote a program to analyze the text. The program found 21,199,528 2-Char sequence occurrences in total. Among the sequences we found, some of them are irrelevant for our consideration, e.g. space-space combination. These sequences are considered as noises, and their occurrences are not included in the analysis . In the data we used to detect the Russian language encodings, this left 20,134, 122 2-Char sequence occurrences. That covers about 95% of all the sequence occurrences found in the data. The sequences used in building our language model can be classified into 4096 different sequences, and 1961 of them appear fewer than 3 times in our 20,134,122 samples. We call these 1961 sequences as Negative Sequence Set of this language.
4.7.1. Algorithm for determining Confidence Level
For single-byte languages, we define the Confidence Level as follows:
Confidence Detecting(InputText)
{
for each character in InputText
{
If character is not a symbol or punctuation character
TotalCharacters++;
Find its frequency order in frequency table;
If (Frequency order < SampleSize)
{
FrequentCharCount++;
If we do not have lastChar
{
lastChar = thisChar;
continue;
}
if both lastChar and thisChar are within our sample range
{
TotalSequence++;
If Sequence(lastChar, thisChar) belongs to NegativeSequenceSet
NetgativeSequenceCount++;
}
}
}
Confidence = (TotalSequence – NegativeSequenceCount)/TotalSequence
* FrequentCharCount / TotalCharacters;
return Confidence;
}
There are several things in the algorithm that need to be explained.
First, this sequence analysis is not done to all characters. We can build a 256 by 256 matrix to cover all those sequences, but many of those are irrelevant to language/encoding analysis and thus unnecessary. Since most single-byte languages use fewer then 64 letters, the most frequently used 64 characters seem to cover almost all the language specific characters. This way, the matrix can be reduced to 64 by 64, which is much smaller. So we are using 64 as our SampleSize in this work. The 64 characters we choose to build our model are mostly based on the frequency statistics with some adjustment allowed. Some characters, such as 0x0d and 0x0a, play roles very similar to the space character (0x20) in our perspective, and thus have been eliminated from the sampling.
Second, for all the sequences covered by this 64 by 64 model, some sequences are also irrelevant to detecting language/encoding. Almost all single-byte language encodings include ASCII as a subset, it is very common to see a lot of English words in data from other languages, especially on web sites. It is also obvious that the space-space sequence has no connection with any language encoding. Those are considered as “noise” in our detection and are removed by filtering.
Third, in calculating confidence, we need to also count the number of characters that fall into our sample range and those that do not. If most of the characters in a small sample data do not fall into our sampling range, the sequence distribution itself may return us a high value since very few negative sequences might be found in such a case. After filtering, most of those characters that have been fed to the detector should fall into the sampling range if the text is in the desired encoding. So the confidence obtained from counting negative sequences needs to be adjusted by this number.
To summarize the foregoing:
- Only a subset of all the characters are used for character set identification. This keeps our model small. We also improved detection accuracy by reducing noise.
- Each language model is generated by a script/tool.
- Handling of Latin Alphabet characters:
- If the language does not use Latin Alphabet letters, Alphabet -letter to Alphabet -letter sequences are removed as noise for detection. (e.g. English words frequently appear in web pages of other languages.)
- If the language does use Latin Alphabet letters, those sequences are kept for analysis.
- The number of characters that fall into our sample range and those that do not are counted so that they can be used in calculating the Confidence Level.
5. Comparison of the 3 methods:
5.1. Code scheme:
For many single-byte encodings, all code points are used fairly evenly. And even for those encodings that do contain some unused code points, those unused code points are seldom used in other encodings and are thus unsuitable for encoding detection.
For some multi-byte encodings, this method leads to a very good result and is very efficient. However, because some multi-byte encodings such as EUC-CN and EUC-KR share almost identical coding points, it is very hard to distinguish among such encodings with this method. Considering the fact that a browser normally does not have a large amount of text, we must resort to other methods to decide on an encoding.
For 7-bit multi-bye encodings like ISO-2022-xx and HZ, which use easily recognizable escape or shift sequences, this method produces satisfactory results. Summarizing, the Code Scheme method,
- is very good for 7-bit multi-byte encodings like ISO-2022-xx and HZ.
- is good for some multi-byte encoding like Shift_JIS and EUC-JP, but not for others like EUC-CN and EUC-KR.
- is not very useful for single-byte encodings.
- can apply to any kind of text.
- is fast and efficient.
5. 2. Character Distribution:
For multi-byte encodings, and especially those that can not be handled reliably by the Code Scheme method, Character Distribution offers strong help without digging into complicated context analysis. For single-byte encodings, because the input data size is usually small, and there are so many possible encodings, it is unlikely to produce good results except under some special situations. Since the 2-Char Sequence Distribution method leads to a very good detection result in such a case, we have not gone further with this method on single-byte encodings. Summarizing these points, the Character Distribution Method
- is very good for multi-byte encodings.
- only applies to typical text.
- is fast and efficient.
5.3. 2-Char Sequence Distribution:
In the 2-Char Sequence Distribution method, we can use more information data in detecting language/encodings. That leads to good results even with a very small data sample. But because sequences are used instead of words (separated by a space), the matrix will be very big if it was to apply to multi-byte languages. Thus this method:
- is very good for single-byte encodings.
- is not efficient for multi-byte encodings.
- can lead to good results with even small sample size.
- only applies to typical text.
6. A composite Approach:
6.1. Combining the 3 methods:
Languages/encodings we want to cover with our charset auto-detector includes a number of multi-byte and single-byte encodings. Given the deficiencies of each method, none of the 3 methods alone can produce truly satisfactory results. We propose, therefore, a composite approach which can deal with both types of encodings.
The 2-Char Sequence Distribution method is used for all single-byte encoding detections.
The Code Scheme method is used for UTF-8, ISO-2022-xx and HZ detection. In UTF-8 detection, a small modification has been made to the existing state machine. The UTF-8 detector declares its success after several multi-byte sequences have been identified. (See Martin Duerst’s (1977) detail). Both the Code Scheme and Character Distribution methods are used for major East Asian character encodings such as GB2312, Big5, EUC-TW, EUC-KR, Shift_JIS, and EUC-JP.
For Japanese encodings like Shift_JIS and EUC-JP, the 2-Char Sequence Distribution method can also be used because they contain a significant number of Hiragana syallbary characters, which work like letters in single-byte languages. The 2-Char Sequence Distribution method can achieve an accurate result with less text material.
We tried both approaches -- one with the 2-Char Distribution Method and the other without. Both led to quite satisfactory results. There are some web sites which contain a lot of Kanji and Katakana characters but only a few Hiragana characters. To achieve the best possible result, we use both the Character Distribution and 2-CharDistribution methods for Japanese encoding detection.
Here then is one example of how these 3 detection methods are used together. The upper most control module (for auto-detectors) has an algorithm like the following:
Charset AutoDetection (InputText)
{
if (all characters in InputText are ASCII)
{
if InputText contains ESC or “~{“
{
call ISO-2022 and HZ detector with InputText;
if one of them succeed, return that charset, otherwise return ASCII;
}
else
return ASCII;
}
else if (InputText start with BOM)
{
return UCS2;
}
else
{
Call all multi-byte detectors and single-byte detectors;
Return the one with best confidence;
}
}
Summarizing the sequences in the code fragment above,
- Most web pages are still encoded in ASCII. This top-level control algorithm begins with an ASCII verifier. If all characters are ASCII, there is no need to launch other detectors except ISO-2022-xx and HZ ones.
- ISO-2022-xx and HZ detectors are launched only after encountering ESC or “~{“, and they are abandoned immediately when a 8-bit byte is met.
- BOM is being searched to identify UCS2. We found that some web sites send 0x00 inside http stream, and using this byte for identifying UCS2 proved to be unreliable.
- If any one of the active detectors received enough data and reaches a high level of confidence, the entire auto-detecting process will be terminated and that charset will be returned as the result. This is called shortcut.
6.2. Test Results:
As a test for the approach advocated in this paper, we applied our detector(s) to the home pages of 100 popular international web sites without document-based or server-sent HTTP charset. For all the encodings covered by our detector(s) we were able to achieve 100% accuracy rate.
For example, when visiting a web site that provides no charset information (e.g. the web site at http://www.yahoo.co.jp before its server started sending the charset info), our charset detector(s) generates output like the following:
[UTF8] is inactive
[SJIS] is inactive
[EUCJP] detector has confidence 0.950000
[GB2312] detector has confidence 0.150852
[EUCKR] is inactive
[Big5] detector has confidence 0.129412
[EUCTW] is inactive
[Windows-1251 ] detector has confidence 0.010000
[KOI8-R] detector has confidence 0.010000
[ISO-8859-5] detector has confidence 0.010000
[x-mac-cyrillic] detector has confidence 0.010000
[IBM866] detector has confidence 0.010000
[IBM855] detector has confidence 0.010000
This then leads to the determination that EUC-JP is the most likely encoding for this site.
7. Conclusion:
The composite approach that utilizes Code Scheme, Character Distribution and 2-Char Sequence Distribution methods to identify language/encodings has been proven to be very effective and efficient in our environment. We covered Unicode encodings, multi-byte encodings and single-byte encodings. These are representative encodings in our current digital text on the Internet. It is reasonable to believe that this method can be extended to cover the rest of the encodings not covered in this paper.
Though only encodings information is desired in our detection results at this time, language is also identified in most cases. In fact, both Character Distribution and 2-Char Distribution methods rely on characteristic distributional patterns of different language characters. Only in the case of UTF16 and UTF8, encoding is detected but the language remains unknown. But even in such cases, this work can still be easily extended to cover language detection in future.
The 3 methods outlined here have been implemented in Netscape 6.1 PR1 and later versions as the “Detect All” option. We expect our work in auto-detection to free our users further from having to deal with cumbersome manipulations of the Character Coding menu. The Character Coding menu (or Encoding menu for others) is different from other UI items in the Internet client in that it exposes part of the i18n backend to general users. Its existence itself is a mirror of how messy today’s web pages are when it comes to language/encoding.
We hope that offering good encoding default and universal auto-detection will help alleviate most of the encoding problems our users encounter in surfing the net. Web standards are shifting toward Unicode, particularly, toward UTF-8, as the default encoding. We expect gradual increase of its use on the web. Such shifts need not be overt as more and more users are freed from confronting issues related to encoding while browsing or reading/sending messages, thanks in part to auto-detection. This is why we advocate good auto-detection and good default encoding settings for Internet clients.
8. Future Work:
Our auto-detection identifies a language. The encoding determination is a byproduct of that determination. For the current work, we only covered Russian as an example of single-byte implementation. Since it identifies a language and only then which encoding it uses, the more language data models there are, the better the quality of encoding detection.
To add other single-byte languages/encodings, we need a large amount of text sample data for each language and certain degree of language knowledge/analysis. We currently use a script to generate a language model for all the encodings for that language.
This work is at present not in the Mozilla source but we hope to make it public in the near future. When we do, we hope people with the above qualification will contribute in this area. Because we have not yet tested many single-byte encodings, it is likely that the model we propose here needs to be fine-tuned, modified or possibly even re-designed when applying to other languages/encodings.
9. References:
Duerst, Martin. 1977. The Properties and Promizes of UTF-8. 11th Unicode Conference.
http://www.ifi.unizh.ch/groups/mml/people/mduerst/papers/IUC11-UTF-8.pdf
Mandarin Promotion Council, Taiwan. Annual survey results of Traditional Chinese character usage.
http://www.edu.tw/mandr/result/87news/index1.htm
Mozilla Internationalization Projects. http://www.mozilla.org/projects/intl
Mozilla.org. http://www.mozilla.org/
Mozilla source viewing. http://lxr.mozilla.org/
이 글은 스프링노트에서 작성되었습니다.
 invalid-file
invalid-file
 invalid-file
invalid-file invalid-file
invalid-file