이 내용은 부채널 공격(Side-Channel Attack)의 대가인 Daniel Gruss의 졸업 논문인 Software-based Side-Channel Attacks and Defenses in Restricted Environments의 내용을 발췌한 것입니다. ^^;;; 저도 그동안 부채널 공격을 관심있게 보지 않아서 대략적인 내용만 알고 있었는데, 이번에 Black Hat Asia의 리뷰보드(Review Board)가 되면서 관심있게 살펴보게 되었습니다.
사실 최근 부채널 공격의 트렌드는 하드웨어 중심이던 예전과 달리 소프트웨어만으로 공격을 한다는 점인 것 같습니다. Daniel Gruss도 이야기하긴 했지만, 예전에는 암호 연산용 칩이 있을 때 암호 연산을 수행하는 알고리즘의 경로에 따라 전력 소모가 달라진다는 점을 이용해서 전력 측정(Power Measurement) 기법을 사용했습니다. 이러한 공격 기법은 현재 대부분 대비가 되어 있는 상태라 새로운 공격 기법이 등장했는데요, 그게 바로 소프트웨어 기반 마이크로아키텍처 공격(Software-based Microarchitectural Attack) 입니다. 주로 캐시(Cache)와 TLB(Translate Look-aside Buffer)를 이용하는데요, 캐시와 TLB에 대해서는 제가 요약한 캐시 및 TLB 부채널 공격(Cache and TLB Side-Channel Attack) 기법을 참고하시길 바랍니다. ^^;;;
소프트웨어 기반 마이크로아키텍터 공격(Software-based Microarchitectural Attack)
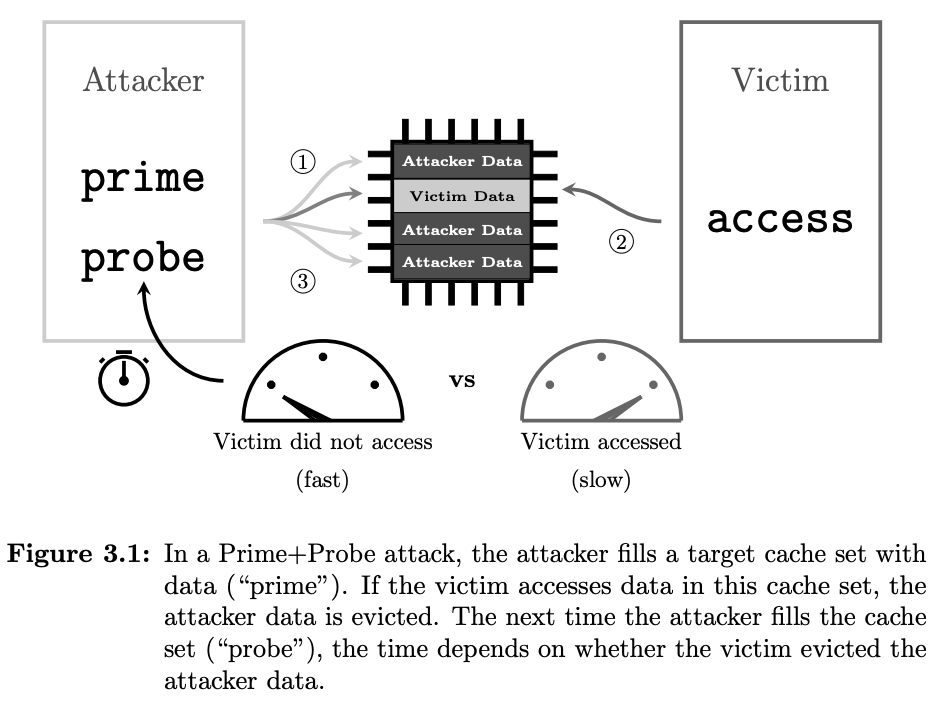
1. 캐시 공격(Cache Attack)
캐시 공격 기법은 연산중에 캐시에 남은 정보를 추출해내는 기법인데요, Evit+Time, Prime+Probe, Flush+Reload, Flush+Flush, Evict+Reload 공격 기법이 대표적으로 최근에 활용된 TLB 공격 기법도 있습니다. 이 부분들은 내용이 많아서 제가 따로 정리한 캐시 및 TLB 부채널 공격(Cache and TLB Side-Channel Attack) 기법를 참고하면 좋을 것 같습니다.
2. 예측자 공격(Attacks on Predictors)
CPU에는 성능을 높이기 위해 다양한 예측자(Predictors)가 들어있는데요, Branch Predictors, Prefetchers, Memory-aliasing Predictors가 있습니다.
- Branch Predictors: 프로그램을 작성하다보면 루프를 사용하게 되는데요, 루프는 일정한 횟수동안 반복해서 도는 특징이 있습니다. 이러한 루프를 만나면 CPU가 루프의 비교문을 만났을 때 다음에도 루프 안쪽을 실행할 것이라고 예측하고 미리 파이프라인에 명령어를 밀어넣는데, Branch Predictors의 예측을 빗나가게 해서 정보를 추출하는 공격 기법이 Branch Predictor Attack입니다.
- Prefechers: 코드를 실행하다보면 현재 실행중인 명령어의 다음 명령어가 실행될 것이라 예측하고 성능향상을 위해 명령어와 데이터를 미리 채워놓습니다. Prefecher는 캐시 부채널 공격을 수행할 때 원치 않는 잡음(Noise)를 생성하는 원인이 되기도 하는데요, Prefecher Attack은 직접 이를 이용해서 공격을 수행하기 보다는 잡음을 줄이는 방법으로 활용되곤 한답니다.
- Memory-aliasing Predictors: 최근 CPU는 실행 능력을 향상시키기 위해 다양한 버퍼(Buffer)를 활용하는데요, Memory-aliasing Predictor는 CPU 내부에 있는 저장 버퍼(Store Buffer)의 값을 캐시에 저장하기 전에 읽어야할 때 이를 읽기 버퍼(Load Buffer)로 옮기는 일을 담당합니다. 저장 버퍼의 값이 읽기 버퍼로 옮겨갈 때 접근 권한(Access Right)가 제대로 검사되지 않으면 정보가 유출될 수 있는데 이것이 바로 Memory-aliasing Predictor Attack입니다. 실제로 Store-to-Leak Forwarding Attack이 이를 이용했습니다.
3. DRAM 공격(DRAM Attack)
DRAM 모듈에 저장된 정보는 Row Buffer를 거쳐서 CPU에게 전달되는데, Row Buffer에 저장된 데이터는 다시 읽었을 때 Row Buffer에 없는 데이터보다 빨리 접근되는 특징이 있습니다. 이러한 공격이 실존하고 이를 이용한 공격이 DRAMA Attack 입니다.

4. 임시 실행 공격(Transient-Execution Attack)
최근 가장 핫한 공격이 바로 임시 실행 공격(Transient-Execution Attack) 인데요, 많이들 알고 계시는 멜트다운(Meltdown), 스펙터(Spectre) 공격 기법이 바로 이 카테고리에 속합니다. 임시 실행 공격은 마이크로아키텍처 공격의 한 종류인데요, 현대 CPU의 비순차실행(Out-of-order Execution)과 예측적 실행(Speculative Execution)을 이용해서 데이터를 유출하는 공격 기법입니다. Daniel Gruss의 전공이기도 하지요.
4.1. 스펙터(Spectre)
스펙터는 임시 실행 공격의 한 종류인데요, 실행 흐름 예측 오류(Control-flow misprediction)과 데이터 흐름 예측 오류(Data-flow misprediction)을 이용합니다. 사실 말보다는 그림으로 보면 더 이해하기가 쉬운데요, 아래는 논문에 있는 스펙터 공격의 흐름입니다.
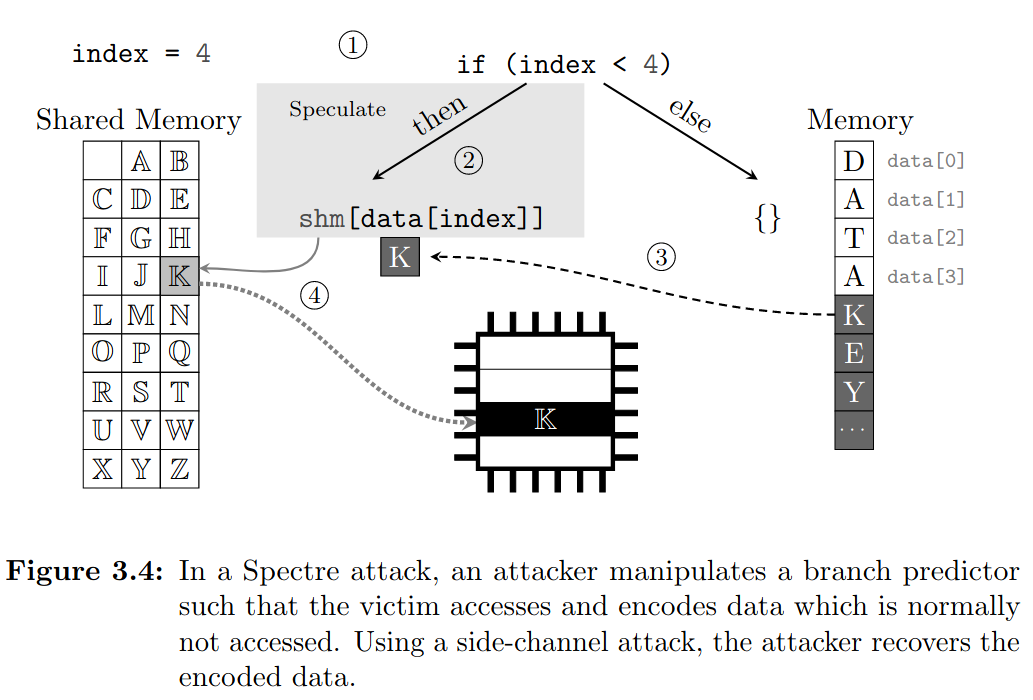
- 위의 그림에서 보는 것처럼 if문 안의 Index가 0~3일 경우는 참이되어 왼쪽의 Then 부분에 코드가 실행됩니다. 따라서 index의 값으로 data 영역을 접근하고 그 값이 공유 메모리 영역인 shm의 index가 되어 최종적으로 값이 읽혀집니다.
- 이때, index의 값을 계속 if문이 True가 되도록 실행을 하면 Branch Predictor가 앞으로도 계속 참이 될 것이라고 예측하고 index의 값이 4보다 커도 Then 영역을 미리 실행(Out-of-Execution)합니다. 즉 예측이 실패하는 것이지요.
- index는 data 영역에서 해당 위치만큼 떨어진 영역을 가리키게 되는데요, 이 index를 주요 정보가 있는 영역, 예를 들어 커널에 저장된 Key가 존재하는 영역이라고 가정한다면 해당 키의 정보가 shm의 Index로 사용되어 캐시에 저장됩니다.
- 마지막으로 공격자는 shm에서 Index만큼 떨어진 영역이 캐시에 저장되었는지를 확인하는 방식으로 주요 정보에 접근할 수 있습니다.
4.2. 멜트다운(Meltdown)
멜트다운은 임시 실행 공격의 한 종류인데요, 예외(Exception)가 발생했을 때 비순차실행(Out-of-order)의 결과로 데이터가 유출되는 것을 노리는 기법입니다. 역시 그림으로 보는 것이 더 이해가 쉬우니 논문의 그림을 인용하겠습니다.

-
위의 그림에서 kernel 부분의 메모리는 접근이 불가능하기 때문에 오류(Exception)이 발생합니다.
-
이때, 비순차실행 때문에 value가 공유 메모리 영역인 shm의 index로 사용됩니다.
-
공격자는 스펙터의 공격기법과 같이 shm에서 Index만큼 떨어진 영역이 캐시에 저장되었는지를 확인하는 방식으로 주요 정보에 접근할 수 있습니다.
지금까지 부채널 공격에 대해서 정리해봤는데요, 최근 부채널 공격은 소프트웨어만 이용해서 공격이 가능한 만큼 파급력이 큽니다. 하지만 다행히도 방어법 또한 마련되어 있는데요, 다음에는 방어법에 대해서 정리해보겠습니다.
그럼 좋은 밤 되세요 ^^)/