Part3. 인터럽트(Interrupt)
들어가기 전에...
- 이 글은 kkamagui에 의해 작성된 글입니다.
- 마음껏 인용하시거나 사용하셔도 됩니다. 단 출처(http://kkamagui.tistory.com)는 밝혀 주십시오.
- 기타 사항은 mint64os at gmail.com 이나 http://kkamagui.tistory.com으로 보내주시면 반영하겠습니다.
- 상세한 내용은 책 "64비트 멀티코어 OS 구조와 원리"를 참고하기 바랍니다.

0.시작하면서...
앞서 커널 개발시에 권장되는(??) 알아야하는 몇가지에 대해서 언급했었다.
그럼 이제 찬찬히 그것들에 대해서 알아볼텐데... 오늘은 인터럽트(Interrupt)에 대해서 한번 볼까 한다.
1.인터럽트(Interrupt)란?
1.1 인터럽트(Interrupt)의 정의
인터럽트(Interrupt)는 내부 or 외부에서 특정한 이벤트로 인해 실행중인 코드를 중단하고 해당 이벤트를 처리하는 예외적인 상황을 말한다. Intel Architecture에서는 이런 예외적인 상황을 아래와 같이 크게 2가지로 구분하고 있다.
- 1.Interrupt : External(Hardware generated) Interrupt와 Software generated Interrupt를 포함.
- 2.Exception : Processor-detected program-error exception과 Software-generated exception과 Machine-check exception을 포함. fault, traps, abort로 구분됨
뭔가 상당히 복잡한데, 위 2가지에 대한 자세한 내용은 여기서 설명하지 않을 것이고, 궁금한 사람은 Intel Architecture Manual의 Volume 2 : Software Developer's Manual을 살펴보기 바란다.
간단히 알아야 할 것만 설명하면, 저런 예외적인 상황은 Hardware 또는 Software 적인 방법으로 발생할 수 있고, 우리가 프로그램을 실행하면서 발생하는 Divide By Zero와 같은 에러도 Exception으로 처리가 된다는 사실이다.
편의상 위의 두가지 모두를 인터럽트(Interrupt)라고 부르기로 하자.
1.2 인터럽트(Interrupt)와 컨텍스트(Context)
내가 소시적에(??) OS를 만들면서 여러책을 보았다. 그때 한 OS 책에서 본 내용이 아직도 기억에 남는데... 그 책은 인터럽트에 대해서 이렇게 설명해 놓았다.
프로그램을 실행 도중, 인터럽트가 발생할 시 현재 작업을 중단하고 상태를 저장한 뒤 인터럽트 서비스 루틴(ISR)을 실행한다. 실행이 완료되면 중단된 시점부터 실행이 재개된다.
여기서 상태를 컨텍스트(Context)라고 이야기하는데, 컨텍스트는 실행중인 프로세스의 내용을 말한다. 위의 항목에서 내가 궁금했던 점은... "상태를 저장한 뒤" 라는 부분... 어느 부분을 어떻게 저장하는 것인지가 명확하지 않았다. 나중에 Intel 메뉴얼을 뒤져서 정확하게 알게 되었지만, 알고 난뒤의 허탈함 and 배신감이란 이로 말할 수 없었다.
과연 "상태"를 어디까지 저장해주는걸까? 아래는 Intel 메뉴얼에 Software Developer's Manual에 나오는 그림이다.
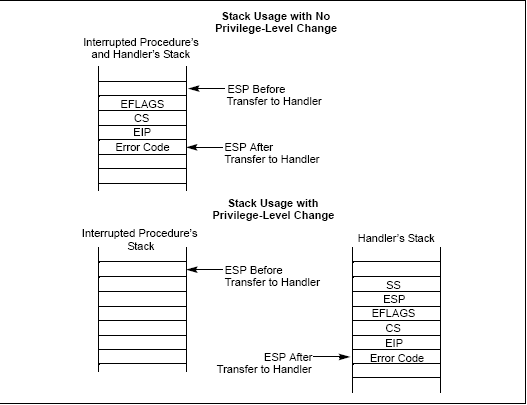
벌써 눈치를 챈 사람들도 있겠지만... 그렇다. 스택(Stack)에 단순히 Flags/CS/EIP/Error Code가 저장되는 것이 전부였다. @0@)/~
그 말은 ISR에서 사용하는 레지스터들은 "알아서" 저장하고 사용한 뒤 "알아서" 복원해야 한다는 이야기다. 위에서 보면 Privilege Level이 변하지 않는 경우는 Flags/CS/EIP/Error Code를 저장하며, 변하는 경우는 SS/ESP를 추가로 더 저장한다. 추가로 저장된 SS/ESP는 인터럽트 처리가 끝났을 때 하위 레벨의 스택으로 다시 돌아가는 용도로 사용하는 것이다.
왜 추가로 더 저장하는가 하니... Intel Architecture는 총 4개의 Level( Ring0 ~ Ring3)을 가지고 Level간에 사용하는 스택을 다르게 설정할 수 있다. Level이 변경될 때 마다 CPU는 해당 Level의 Stack으로 변경해 주게되고 이것을 Stack Switching이라고 부른다(모든 레벨이 같은 스택을 사용할 수도 있다. 일단 Level이 다르면 Intel CPU는 SS/ESP를 Handler의 스택에 저장해 준다는 것만 알아두자.)
2.인터럽트의 처리
2.1 인터럽트 서비스 루틴(Interrupt Service Routine-ISR)의 컨텍스트(Context) 저장
커널을 만들려면 위에서 언급했던 인터럽트들을 처리해 주는 인터럽트 서비스 루틴(Interrupt Service Routine-ISR)을 만들어야 하는데, 보통 아래와 같은 형태를 띈다.
_kIsr :
** pushad**
** push ds
push es
push fs
push gs <== 여기까지가 컨텍스트(Context)를 저장하는 부분**
; 일단 커널 쪽에 진입해야 하므로 세그먼트 재 설정
mov ax, 0x10
mov es, ax
mov ds, ax
mov fs, ax
mov gs, ax
**call HandlerFunction <== Handler 함수 호출 부분 **
** pop gs
pop fs
pop es
pop ds
popad <== 여기까지가 컨텍스트(Context)를 복구하는 부분
iretd <== 인터럽트 처리 완료후 복구하는 부분**간단히 설명하면 위의 파란색 부분은 사용할 레지스터들은 저장하고 핸들러 루틴을 불러서 필요한 처리를 한다음 다시 복원하는 코드이다. 붉은 색 부분은 실제로 스택에 저장된 Flags/CS/EIP 및 SS/ESP를 복원하고 코드로 돌아가는 코드이다.
크게 어려운 어셈블리어 명령이 아니기 때문에 설명은 다음으로 미룬다. @0@)/~ 궁금한 사람은 역시 메뉴얼을 참조하면 된다.
2.2 핸들러 루틴(Handler Routine)
지금까지 ISR의 컨텍스트 저장 코드에 대해 간단히 보았다. 이제 HandlerFunction이 무엇을 하며 어떻게 작성해야 하는지 한번 알아보자.
인터럽트가 발생하면 원인이 Interrupt인가 Exception인가에 따라서 HandlerFunction의 실제 역할이 다르고, Interrupt or Exception의 세부분류에 따라 그 역할이 다르다.
보통 Handler는 C 함수로 작성되고 우리가 흔히 알고 있는 일반 함수 코드 처럼 작성된다. 아래는 프레임워크에서 사용된 키보드 핸들러의 소스코드이다.
//-----------------------------------------------------------------------------
//
// 키보드 핸들러 버퍼에 값을 집어 넣는다.
//
//-----------------------------------------------------------------------------
void kIsrKeyboard( void )
{
BYTE bCh;
bCh = kReadPortB( KBD\_PORT\_BUFFER );
kPrintchxy\_low( GDT\_VAR\_VIDEOMEMDESC, 11, 0, bCh, 0x05 );
// 키를 버퍼에 넣는다.
kAddKeyToBuffer( bCh );
// Bottom Half 사용
g_stBottomHalfManager.vstBottomHalfUnit[ 1 ].bFlag = TRUE;
kSendMasterEoi();
}우리가 흔히 쓰는 함수와 같은 형태를 하고 있으니 이해하는데는 문제가 없을 것이다. 코드를 보면 키보드 포트에서 값을 읽어서 버퍼에 저장하는 역할을 한다는 것을 금방 알 수 있다.
그렇다면 ISR 함수와 우리가 사용하는 일반 함수와 차이점이 무엇일까? 함수가 불리어지는 시점의 차이가 가장 큰 차이다.
ISR은 인터럽트가 발생한 시점에서 호출되는 코드이기 때문에 장시간 걸리는 작업을 실행하면 시스템 전체의 성능에 영향을 미치게 된다. 인터럽트가 발생하면 CPU에서 기본적으로 인터럽트를 불가 상태로 만든다음 ISR 함수를 호출하게 된다. 다시 말하면 ISR 처리 루틴이 완전히 끝나지 않는 한 다른 인터럽트가 발생하지 못한다는 것이다. 이것은 아주 치명적인데, 예를 들어 특정 인터럽트 루틴에서 무한루프를 돌면 키보드/마우스/타이머 등등이 먹통이된다. @0@)/~!!!!
2.3 주의해야 할 점
** ISR에서 절때 시간이 많이 걸리는 작업을 해서는 않된다.**
이것은 진리이며, 자칫 잘못하면 시스템 전체의 성능을 느리게 만든다. 예외 핸들링 시 레벨에 따라서 우선순위가 다르기 때문에 낮은 Level의 예외는 지연되게 되므로 더욱 세심한 배려가 필요하다. 최상위 Level의 핸들링에서 처리가 늦게되면 그 외에 낮은 Level의 예외는 당연히 지연될 수 밖에 없다.
인터럽트의 Level에 대한 분류는 가장 높은 것이 Hardware Reset과 Machine Checks이고 그 밑으로 이것 저것 있는데, 역시 궁금한 사람은 Intel Architecture 메뉴얼을 참조하도록 하자.


그리고 잊지 말아야 할 사실을 다시 한번 강조한다.
*인터럽터가 발생하면 기본적으로 ISR 핸들러 호출 시 EFLAG 레지스터의 인터럽터 가능 플래그가 0으로 되어 Disable된 상태라는 것이다. *
이 말은 인터럽터 핸들러 안에서 무한루프를 돌면, 그 외에 다른 인터럽터도 발생하지 않는다는 말과 동일하다. 따라서 각별한 주의가 필요하다.
3.인터럽트(Interrupt)의 처리흐름
인터럽트가 발생하면 수행중인 태스크는 중지되고 인터럽트 핸들러가 호출된다고 했다. 이것을 그림으로 표현하면 아래와 같다.

특정 태스크가 실행중이다가 인터럽트가 발생하면 인터럽트 핸들러에서 인터럽트에 대한 처리가 되고, 그것이 완료된 다음에야 태스크로 복귀한다.
핸들러에서 작업이 늦게 끝나면 끝날수록 태스크로 복귀하는 시간이 늦어지며 이 시간 동안 거의 인터럽트가 불가능해서 전체적인 지연을 초래하는 것이다. 물론 요즘 커널들은 인터럽트 핸들러 안에서도 인터럽트가 발생할 수 있도록 하여 더욱 가용성을 높이고 있다.
인터럽트의 중복을 허용함으로써 오는 이득은 특정 인터럽트가 완료되지 않은 상태에서 다른 인터럽트의 처리가 가능하므로 많은 인터럽트를 다중으로 처리할 수 있다는 점이다. 대신 인터럽트가 다중으로 발생할 수 있으니 커널코드 자체도 재진입(reenterance) 가능하도록 해야 되니 커널 코드가 굉장히 복잡해 지는 단점을 가지고 있다.
커널 코드 내에서 인터럽트 발생이 가능하도록 한 좋은 예제로 Linux Kernel 2.6 버전이 있다. 커널이 2.6 버전으로 올라가면서 스케줄러 부분 및 메모리 관리 부분이 비약적으로 향상되었다는데, 궁금한 사람은 참고하는 것도 괜찮을 듯 하다.
5.마치면서...
인터럽트에 대한 위 내용 정도의 지식은 거의 필수라고 볼 수 있다. 이번 내용에서 깊은 내용은 다루지 않고 개론 정도만 언급했으므로 알아두도록 하자.
4.첨부
'OS Kernel > 32bit OS Framework' 카테고리의 다른 글
| Part5. Intel Architecture에 대한 소개 (2) | 2007.11.14 |
|---|---|
| Part4. 어셈블리어(Assembly Language)와 C 그리고 호출 규약(Calling Convention) (0) | 2007.11.14 |
| Part2. 커널 개발시 꼭 알아야할 몇가지 (0) | 2007.11.14 |
| Part1. 커널 개발이 힘든 이유 (7) | 2007.11.14 |
| 00 KKAMA OS (0) | 2007.11.14 |

